1. Hunter 介绍
在上一篇文章中提到, 我们公司系统是一个多语言的异构环境, 各服务间通过Thrift或者Http进行RPC调用. 为了提高系统整体的可观测性, 我们在Q3开始时着手研发多语言全链路跟踪系统 Hunter, 经过几个月的努力, Hunter 终于如期上线!
Hunter: 猎人、猎狗. 取意跟踪、追踪
Hunter 目前的状态如下:
- 支持公司主要语言, 目前包括Java, Golang和Node.js, 后续将继续提供对Ruby项目的跟踪支持.
- 支持以上语言间的Thrift 和Http调用, 也支持对外网Http请求的跟踪.
- 支持多种存储跟踪, 包括Mysql, Redis, Memcached, CouchBase等
- 支持公司常用的web框架, 包括Java tomcat, tomcat-embedded, Golang beego, Node.js Koa
- 支持业务数据在跟踪链上透明传输
- 支持链路跟踪反查
- 接入项目无感知, 低入侵植入
本文将介绍一下Hunter的部分实现.
1. 系统组成
在上一篇文章中提到, Hunter 是基于OpenTracing协议, 同时参考了业务一些优秀的跟踪框架, 其中包括Uber在今年开源的跟踪框架Jaeger, 受限于系统的差异, Jaeger不能在我们系统上开箱即用, 主要是因为:
-
Uber 采用的内部RPC是基于自研的TChannel, TChannel自带跟踪信息, 在Uber系统中广泛应用. 而我们公司系统使用了多年的Thrift+自研的服务治理框架, 要求各业务团队替换RPC框架几乎不可能, 我们需要基于Thrift实现各语言跟踪注入.
-
开源的Jaeger目前还在快速迭代中, 缺乏压测数据, 存在潜在的bug风险. 同时当时释出的版本存储只支持Cassandra(注: 目前Jaeger可以通过Plugin的形式使用ES, 感谢开源), Cassandra并不在我们公司技术白名单中, 公司内部倾向于使用以及广泛推广的ES做存储.
-
另外我们的全链路跟踪目标是针对已有系统现存的技术栈, 因此我们的Client代码植入的目标组件更有针对性, 这能减少我们的维护成本.
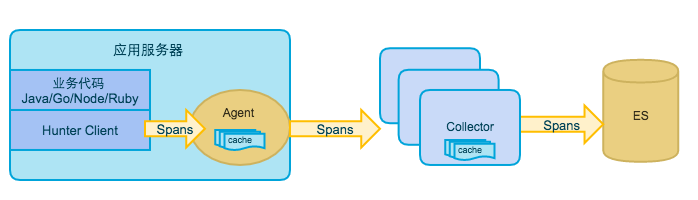
不过我们仍然参考了Jaeger的系统实现, 采用Client植入、 Agent采集、Collector进行数据清洗和入库的架构, 主要的区别是我们在数据传输方式上使用了原生的Thrift, 数据存储使用ES, 同时按需定制了植入各语言项目的Clinet.
2. 跟踪植入
Hunter 能否顺利推广的关键在于Hunter Client 对宿主项目的入侵度, 理想的情况是各项目只需要一行引入代码, 就能实现全链路跟踪的功能, 比如Node.js 只需要:
const Hunter = require('hunter_node');
const hunter = new Hunter({ serviceName: 'my_project_name'});
跟踪植入主要包括:
- 跟踪注入: 结合调用链依赖的标准库或者第三方库, 确定跟踪的起止代码端点
- 跟踪信息维护: 包括跟踪信息的自动创建、存储、传递以及父子关系梳理等
2.1 跟踪注入
跟踪埋点需要根据跟踪目标依赖的代码进行定制, 常见的方案有:
- 利用动态语言的Method Proxy、Monkeypatching, 扩展目标API跟踪功能
- 对于符合装饰者模型的跟踪对象, 新增跟踪装饰者
- 对于扩展限制严格的目标对象, 比如golang的跟踪对象, 采用功能重写, 但是要尽量减少业务项目引入的工作量, 比如client发布时需要有同名的tag, 或者把引入工作提前到基础模块中.
- Java Agent: 通过java提供的premain和agentmain机制,在加载每个应用的main方法之前能够添加一些回调,动态增强字节码(transform),达到埋点的目的。
2.1.1 Monkeypatching
Ruby提供的alias可以比较方便的实现Monkeypatching, Hunter 的 Node.js Client 也是类似的实现, 本质上是利用了这些动态语言允许方法重写这一特性.
# 原始的API, 是我们要跟踪的目标
def do_http
puts "do http ......"
end
# 跟踪 client 采用Ruby提供的命名环绕
# 对旧的API进行跟踪功能扩展
# 本质上是Monkeypatching
alias :original_do_http :do_http
def do_http
puts '开始跟踪, 记录相关信息'
original_do_http
puts '结束跟踪, 记录相关信息'
end
# 业务代码的调用方式和以前保持不变
do_http
# 输出:
# 开始跟踪, 记录相关信息
# do http ......
# 结束跟踪, 记录相关信息
2.1.2 Decorator
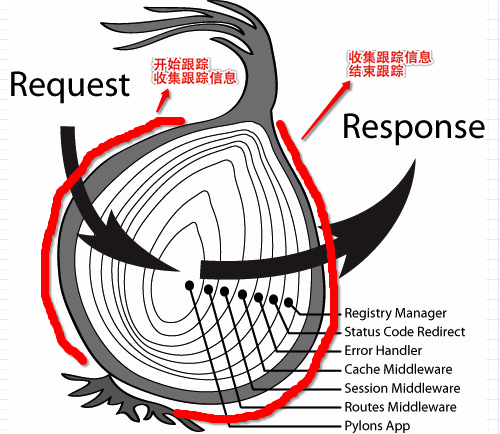
比如Node.js团队用得比较多的web框架koa采用典型的装饰者模式, 其应用实例持有一个middleware数组, 各middleware之间层层包裹, 业务代码在最里面, 也就是常说的洋葱模型.
我们认为, 一次koa HTTP 跟踪的起止包括所有middleware耗时, Hunter Node Client 要做的就是给这个洋葱最外层新加一层跟踪的「洋葱皮」, 也就是将跟踪的中间件放到middleware数组的第一个. 这个跟踪的中间件将负责记录起止时间, 并记录跟踪感兴趣的其他数据, 比如状态码, 错误信息等:
2.1.3 Golang 注入方案
有人曾把编程语言分为魔幻语言和简约语言两大类, 以全面简单(Overall Simplicity)为价值观的Golang 正是典型的简约语言, Golang没有提供诸如「method proxy」「monkeypatching」这类黑魔法, 而是强调用代码明确地表达意图. 就RPC而言, Golang 提倡利用API的第一个参数来传递context.
利用Context#WithValue, 可以将一组键值对数据绑定到一个context实体上, context在RPC之间传递带动绑定数据的传递, 在链路跟踪场景中, 绑定数据就是跟踪信息(Span).
我们也曾尝试了一些Golang关于monkeypatching的第三方实现, 比如Go monkeypatching, 的确是可以实现, 但是因为显而易见的扩展性和安全性考虑, 我们还是没有对此做过多的尝试. 最终我们还是遵循Golang提倡的理念, 通过函数首参传递跟踪信息. 这需要宿主项目修改少量代码, 不过我们尽量将其控制在项目的基础模块中.
2.2 跟踪信息维护
一次完整的调用链会经过分布在不同机器的若干项目, 而对于途径的每个项目, 都会生成若干Span, 这些Span在完成之前会占用应用内存, 每个Span需要和具体请求、事务关联起来. Span 之间还涉及到跟踪上下文的传递和关系梳理.
Span的维护机制在各语言中有所不同, 最简单的情况是单进程式+同步调用的平台, Span之间的起止关系一直是串行的.
2.2.1 Java
对于多线程平台, 通常实现是将跟踪信息存储于ThreadLocal区域, 比如Java, Threadlocal是存在于线程对象上的一个存储区域,可以在线程中独享,Span在Start后会存储到该区域, 在需要时(比如Finish)再从Threadlocal中取出span对象进行操作.
对于多线程+异步调用平台, ThreadLocal还不够, 比如Java里经常需要创建新线程执行异步操作, 这类跟踪需要在线程创建时传递跟踪信息, 在Java客户端里抽象为continuation, continuation传递到了线程中,最终在线程执行完成的时候后完成关闭span, 完成一个链路:
class TracedRunnable implements Runnable {
private final Runnable delegate;
private ActiveSpan.Continuation continuation;
public TracedRunnable(Runnable delegate, ActiveSpan activeSpan) {
this.delegate = delegate;
if (activeSpan != null) {
this.continuation = activeSpan.capture();
activeSpan.close();
}
}
@Override
public void run() {
try (ActiveSpan activate = continuation.activate()) {
delegate.run();
}
}
}
2.2.2 Golang
Golang 在语言级别支持并发, 其并发单元goroutine是一种用户态的线程, 最开始我们希望能最大程度地降低Hunter 对业务代码的入侵度, 消除跟踪信息在业务代码中的显示传递是其中关键一环, 我们调研过goroutine local storage, 获取goroutine id将跟踪信息关联存储, 但是这并不符合Golang的理念, 可能会有潜在的性能问题. 最终我们还是采用函数首参传递context的形式来维护跟踪信息, 对我们来说这并不完美, 但公司的Golang业务团队还是可以接受这种实现.
2.2.3 Node.js
Node.js 是典型的异步IO平台, 异步操作和对应的回调处理无法简单的串联, 我们无法从主线程的执行顺序来判定这两个操作是否是同一个调用链. 我们可以类比一下Node.js 中error的传递方式, error通常是在callback链路中作为第一个参数进行传递, 这其实是将异步链路进行串联的一种方式: 显式传递. Golang 中通过context传递来串联跟踪链属于就此类型.
不过在 Node.js 中有更好的选择, 使用Continuation-Local Storage 或者Node.js 8 中新增的 Async Hooks. 因为我们在之前已经升级到Node.js 8, 我们在Hunter Node Client 中直接尝试了Async Hooks.
Async Hooks 将异步操作实例化为为异步资源对象(asynchronous resources), 并抽象了异步资源的生命周期, 这些生命周期上可以注册回调方法:
- 初始化, 对应注册回调:
init - 回调之前, 对应注册回调:
before - 回调之后, 对应注册回调:
after - 销毁后, 对应注册回调:
destroy
每个异步资源有自己的标识ID, 另外triggerAsyncId代表着触发本次异步资源的上层异步资源ID. 在init/before/after/destroy等回调中, 我们有机会将异步资源构建成一颗调用树. 这给我们进一步做链路跟踪和分析提供了便利.
asyncHooks.createHook 用于注册以上回调, 示意代码:
asyncHooks.createHook({
init(asyncId, type, triggerAsyncId, resource) {
// 组织id 和 triggerIdd的父子关系, 构建异步资源调用树
},
before(asyncId) {
// 记录asyncId为_currId, _currId用于任何时候找到当前异步资源
},
after(asyncId) {
},
destroy(asyncId) {
}
});
以上代码动态维护着异步资源调用树, _currId好比一个游标, 指向当前正在运行的节点, 每个节点是资源id和业务数据(data)的组合, 在Hunter Node Client 中, 这个业务数据就是跟踪信息(span). 任意时刻都可以通过_currId找到当前的异步资源, 并进行跟踪信息的读写.
其实这个方案有点类似Golang的Context, 传递的Context也是一个树形结构, 同时WithValue的Context也可以携带跟踪数据. 不同的是Golang Context需要显示在调用间传递, 而Async Hooks可以在业务代码中隐藏这些操作.
3. 数据流转
3.1 Span
Span 是链路跟踪的最小单元, 代表诸如一次RPC调用, 或者一次存储查询. 多个相关的Span组成一次完整的Trace.
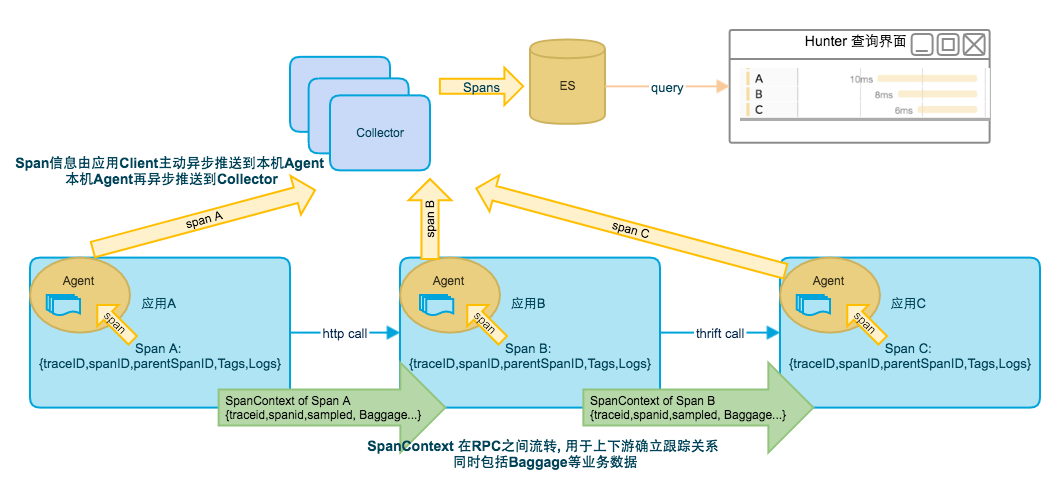
Span 是由目标项目中植入的Hunter Client生成, Client 会异步地将Span 推送到本机Agent, Agent 再将Span异步批量提交到Collector.
3.2 SpanContext
项目之间的关系产生于RPC调用, 包括Http和Thrift. 各语言的Client还需要负责在RPC调用之间传递必要的跟踪信息, 这类需要在应用之间传递的信息叫做SpanContext.
SpanContext通常包括上级Span的基本信息, 用于下级创建Span设置关系. 另外SpanContext还可以包括应用感兴趣的业务信息, 比如订单号或者用户id. 这类信息叫做Baggage, 这可以实现数据在应用间透明传输. 见一节图示.
整体的数据流转图如下:
为了尽量减少Clinet对宿主应用的性能损耗, 各语言Client主要有以下2点措施:
- 异步推送到Agent: Client生成Span后将其缓存在内存中, 定时异步批量推送给Agent. 不同的语言存在不同的异步方案(setInterval/多线程/goroutine)
- 缓存大小触发推送: 如果内存中的缓存Span大小超过了规定大小, 也会触发批量推送, 这主要是避免在高并发时造成的内存急剧膨胀.
- 采样率控制: 通过主动积极的采样率控制, 可以主观地调节跟踪信息收集量和应用性能损耗之间的权衡.
3.3 数据透明传输
链路之间传递的Baggage会跟随SpanContext向下传递, Baggage可以用于承载业务感兴趣的数据, 实现数据在应用间透明传输:
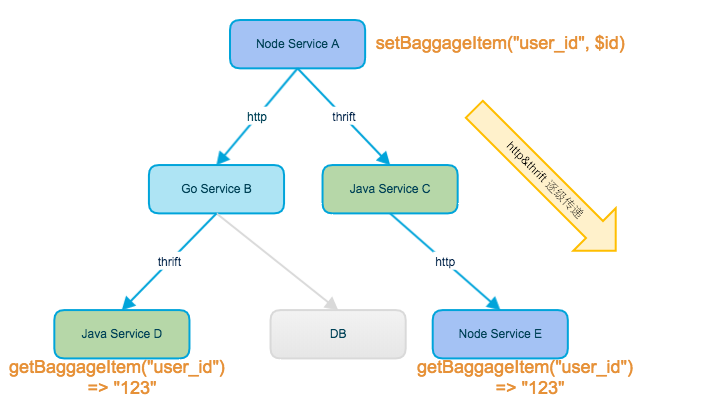
各语言Client都提供了Baggage的读写方法. Baggage在Http中是通过Response Header 传输, 在Thrift中是通过注入到特殊参数位上实现. 太大的业务数据会导致RPC性能低下, 通常建议仅通过Baggage传递的业务数据是一些精炼的ID, 比如user id, order id等.
4. 跟踪反查
异构的语言架构导致系统可观测度降低, 每个季度总结时都有很多遗留未解决的不可重现bug, 不可重现的bug不等于非错, 相反这些bug有着确凿的异常表现, 只是因其偶发性而不能定位到根本原因.
对于Hunter来说, 我们希望用户触发的每一次请求, 都像一次购买下单一样, 在系统中可以做到细节可查, 类似订单有订单号, 请求链路也有自己的唯一标识, 就是上文中提到的Trace ID.
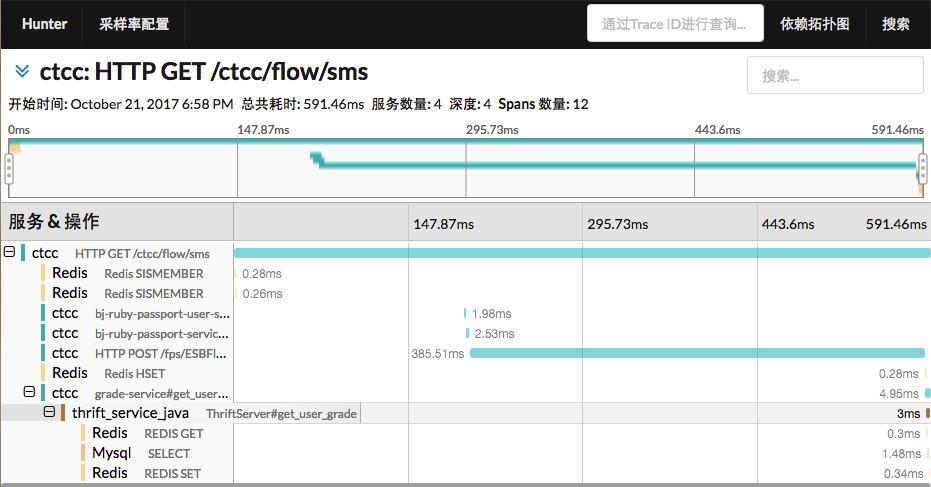
为了利于系统排查, 我们注入了各语言Web框架的Http处理, 将Trace ID作为Response Header 返回给用户, 取名为Hunter-Id, 当用户请求发生异常时, 我们可以提取 Hunter-Id 到 Hunter Web中进行链路查询, 从而可以很快定位到异常原因:
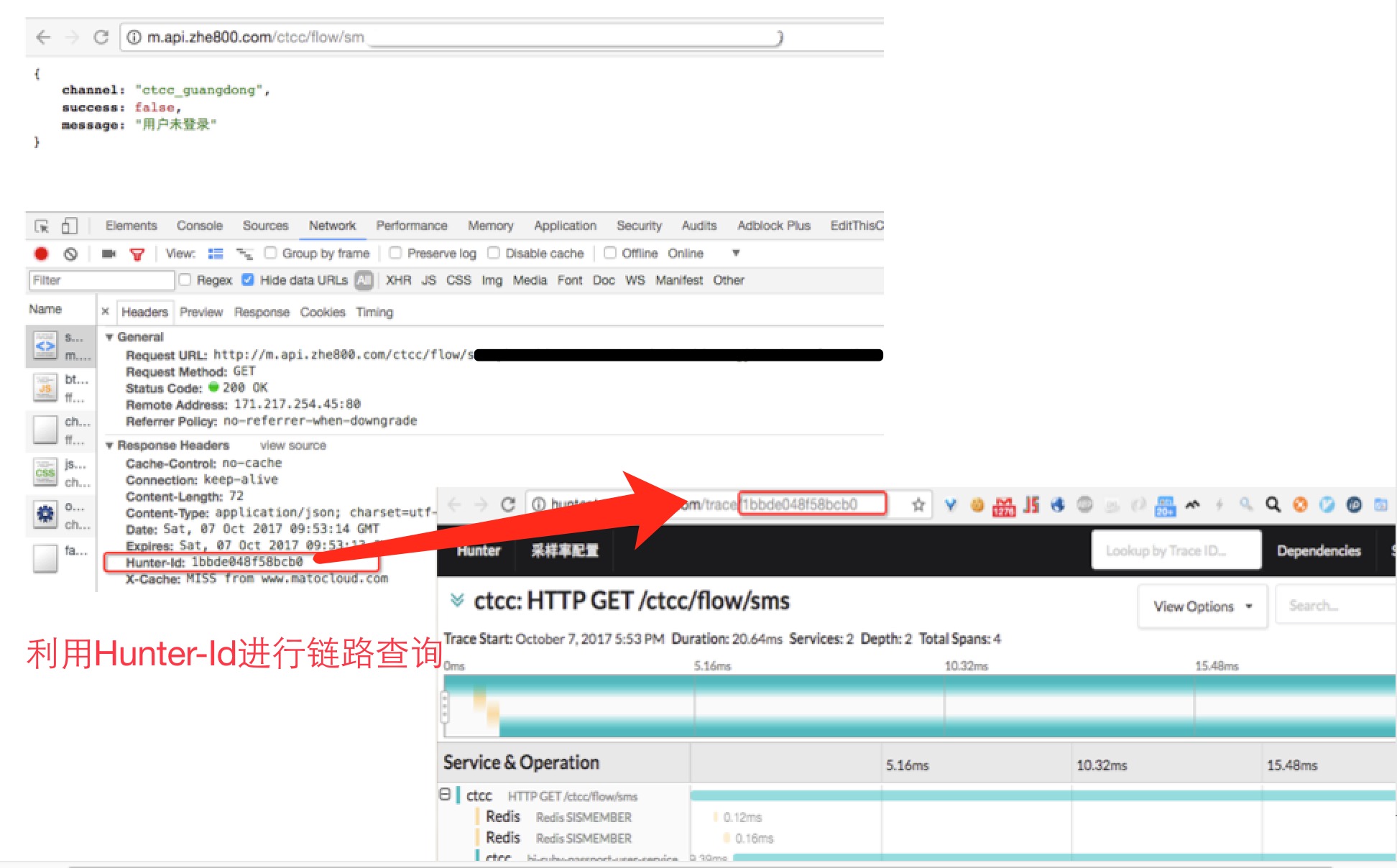
不过这里还留了一个优化未完成, 在上报异常时, 普通用户可能不知道如何提取Response Header, 我们后期打算将Hunter-Id注入到Http Body中, 出现异常时自动展示出来.
5. 未来计划
公司已经有若干项目接入Hunter, 链路跟踪带来好处已经初步显现, 目前Huner 已经可以应用到网络优化、瓶颈查找、链路优化等日常监控和排查过程中.
全链路跟踪系统对系统可观测能力的提升, 还有很大的想象空间. Hunter 后续工作仍然任重道远, Hunter 收集到的跟踪信息, 进行数据处理和统计分析后, 还有很多的应用场景, 比如通过跟踪信息中的耗时或者错误进行自动报警, 结合跟踪信息中的流量变化进行自动伸缩等等.
以下是一些优先级较高的 TODO 事项:
-
在可接受的性能损耗范围内, 进一步提升各语言项目的采样率.
目前压测结果显示, 如果开启全量采样, 项目性能(吞吐率等指标)损耗大概在10%, 有的项目甚至超过20%, 这是业务系统无法接受的, 目前我们默认的采样率是千分之一, 可以把性能损耗控制到5%以下, 5% 是业务方可以承受的范围. 采样率可以在Hunter 后台进行主动调整, 覆盖默认值, 对于一些请求压力比较小的关键服务, 可以适当提高采样率.
采样率的提升有助于提升整个系统的可观测性, 但是这需要我们对植入Client代码仔细打磨, 提升性能, 降低损耗.
-
构建项目依赖拓扑图
在我们公司, 一个服务的规格或者调用方式需要调整时, 这个服务的负责同学会广发邮件, 通知兄弟部门进行调用依赖排查. 这种事情每个季度总会出现若干次, 繁琐且不可靠.
Hunter 已经采集到了项目间实时的调用关系, 我们可以实时梳理出服务的调用方, 或者某个存储的调用方, 包括成功和失败的调用次数. 这种关系可以精确到分布式服务的任何一台具体的服务器. Hunter以及有了这些原始数据, 我们需要借助Spark等数据处理工具进行处理并展示.
-
Hunter Ruby Client 的开发
Ruby是公司最早使用的开发语言, 目前已经逐渐减少使用, 主要集中在后台管理系统业务中. 不过还是有部分http服务是Ruby项目提供的.
Ruby 主要采用的是阻塞IO, 没有异步语言的跟踪链维护困扰. Ruby语言本身比较自由, 同时提供了强大的元编程技术, 这些使得实现Ruby的跟踪客户端相对比较容易.
-
扩展其他类型存储跟踪